
Opened 9 years ago
Closed 8 years ago
#9282 closed Bugs (fixed)
performance regression in boost::unordered on 64-bit platforms
| Reported by: | Owned by: | Daniel James | |
|---|---|---|---|
| Milestone: | Boost 1.56.0 | Component: | unordered |
| Version: | Boost 1.53.0 | Severity: | Regression |
| Keywords: | unordered mix64_policy performance | Cc: |
Description
On 64-bit platforms boost::unordered containers use 'mix64_policy' which doesn't grow the bucket count as fast as the 'prime' version. That makes adding items to an empty/'non-reserved' container extremely slow. Changing new_bucket_count/prev_bucket_count should fix the problem. Versions affected: 1.50 and above.
Regards,
- Ildar.
Attachments (2)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (14)
comment:1 by , 9 years ago
comment:2 by , 9 years ago
| Status: | new → assigned |
|---|
Could you tell me what values you're inserting? I want to work out if this is a bug in the implementation, or if it's a weakness in the mix function. If you can't give the actual values, is there a pattern they follow?
comment:3 by , 9 years ago
I believe it's the weakness of the mix function - taking it out (just using hf(x)) actually improves performance versus the prime_policy. I understand that you use the mix function to avoid collisions with simple hash-functions and I was also looking into a way to improve it. The test I use is simple - add 100M of 64-bit index combined with 0x9876543200000000 (any number above 32 bits) in reverse order, then make sure they all exist, then fetch for non-existing records. The code snippet:
inline uint64_t NewID(size_t i) {
return (0x9876543200000000ULL | i);
}
void test() {
printf("Fill: boost::unordered_set (64K)\t"); boost::unordered_set<uint64_t> ids(65536);
size_t N=100000000; 100M records size_t i=0; for(; i!=N; ++i)
ids.insert(NewID(N-i));
printf("Fetch: boost::unordered_set (64K)\n"); for(i=0; i!=N; ++i) {
if (ids.find(NewID(i+1))==ids.end()) {
printf("\nFailed!\n"); break;
}
}
printf("Fetch: boost::unordered_set invalid records\n"); for (i=0; i!=N; ++i) {
if (ids.find((uint64_t)(i | 0xF0000000UL))!=ids.end()) {
printf("\nFailed!\n"); break;
}
}
}
Thanks for looking into it.
comment:4 by , 9 years ago
This particular benchmark hits the best case behaviour for the prime policy, so it should be a bit faster than the mix policy. You're inserting consecutive values which will result in no collisions when using the prime policy, but for the mix policy the bucket should be chosen pseudo-randomly which means there will be some collisions. But in theory that result shouldn't happen in general.
I wouldn't deny that some may consider that best case desirable, so it might be worth using the prime policy for integer types. But I first want to check that is what's happening here, and not something worse.
I'm currently using a 32 bit operating system, which makes running your test a bit tricky, so can you try running this with the resulting container to get an idea of how many collisions there are:
#include <map>
#include <iostream>
#include <boost/unordered_set.hpp>
#include <stdint.h>
void bucket_histogram(boost::unordered_set<uint64_t> const &x) {
typedef std::map<std::size_t, std::size_t> map;
map frequencies;
std::cout << "Bucket count: " << x.bucket_count() << std::endl;
for (std::size_t i = 0; i < x.bucket_count(); ++i) {
++frequencies[x.bucket_size(i)];
}
for (map::const_iterator i = frequencies.begin(); i != frequencies.end(); ++i) {
std::cout << i->first << " " << i->second << std::endl;
}
std::cout << std::endl;
}
The output for the prime policy should be something like:
Bucket count: 100663319 0 663319 1 100000000
i.e. no collisions. All buckets either have 1 element, or no elements.
The output for the mix policy should be something like:
Bucket count: 134217728 0 63716044 1 47468076 2 17685158 3 4390091 4 819351 5 122072 6 15183 7 1564 8 176 9 13
i.e. up to 9 collisions.
I got those values by running a simulation of the container. If it's significantly worse than that, then there's definitely a bug.
In theory, the average frequencies should follow the poisson distribution with lambda = number of elements/number of buckets:
0 63714059.8155024
1 47470673.7812626
2 17684204.0498788
3 4391919.58553563
4 818058.771181037
5 121900.256154096
6 15137.1280543625
7 1611.14846535692
8 150.049893684399
9 12.4217647383941
10 0.925493593394311
Which is pretty similar to the results my simulation got.
comment:5 by , 9 years ago
It just occurred to me that my old laptop is running a 64 bit operating system. It only has 2 GB memory, so I couldn't run it for as many records. I ran it for 30M records and I got the kind of distribution I'd expect.
But the performance was worse than I expected (about twice as long for the mix policy). I'm not sure, but I think it might be because of bad cache coherency. The mix policy is jumping around the buckets array, while the prime policy is moving through it linearly. So even if there's an empty bucket the mix policy is much more likely to have a cache miss when checking the bucket. I'll think about this.
by , 9 years ago
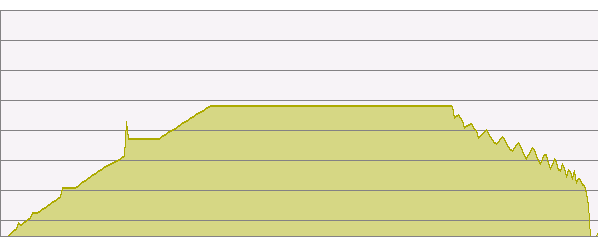
| Attachment: | boost_unordered_mix.png added |
|---|
memory usage - boost::unordered_set using mix64_policy
by , 9 years ago
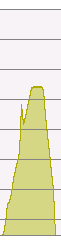
| Attachment: | boost_unordered_nomix.png added |
|---|
memory usage - boost::unordered_set using mix64_policy WITHOUT the mix code
comment:6 by , 9 years ago
I attached diagrams showing memory usage with and without the mix function. You can see that memory is used differently - the first one has longer bucket-chains. Peak memory usage is the same for both - 4GB.
And you were right about the histograms (the time is in seconds):
With mix code:
Fill: boost::unordered_set (64K) - 00:52 Bucket count: 134217728 0 63716044 1 47468076 2 17685158 3 4390091 4 819351 5 122072 6 15183 7 1564 8 176 9 13 Fetch: boost::unordered_set (64K) - 00:15 Fetch: boost::unordered_set non-existing records(64K) - 00:18 Total time: 01:41
Without the mix code:
Fill: boost::unordered_set (64K) - 00:07 Bucket count: 134217728 0 34217728 1 100000000 Fetch: boost::unordered_set (64K) - 00:01 Fetch: boost::unordered_set non-existing records (64K) - 00:00 Total time: 00:09
comment:7 by , 9 years ago
| Milestone: | To Be Determined → Boost 1.56.0 |
|---|
Just to let you know that I haven't forgotten about this. I'm not sure how I'm what action I'll take (if any) it, but I'll try to resolve this for 1.56.0.
comment:8 by , 9 years ago
Came across this yesterday. Pardon the unsolicited feedback, but it's hard to imagine what one could do to resolve this in the general case; as noted above, the combination of identity function hash_value<int> + the insertion order strongly favors the implementation w/o Wang's mixing function (best case) or the prime policy, both for collision avoidance (low bits of all keys are unique) and for more efficient use of the cache write buffer.
One possibility would be to expose the bucket policy as a top-level template parameter, so that users can pick an appropriate strategy in the rare occasions that the default is inappropriate(*). As a small side note, a third policy w/ power-of-two table size that doesn't perturb the hash value would be slightly more efficient when we know that the hash function distributes well over the lower bits (e.g. hash_value<std::string>).
(*) It's hard to imagine when this would be; if you know that you're filling the set/map with entries that will hash to unique consecutive buckets during insert, a different data structure might be worthwhile.
comment:9 by , 9 years ago
Thanks for the feedback. Exposing the policy is a good idea, but I'm not keen on adding an extra template parameter, so I'm thinking about adding a type trait for the hash function, which would let someone using a custom hash function indicate which strategy it is suited for. Actually, I'll bring up that up on the development list now.
I decided in the end to use a prime policy for integers in the next release. This is slower in general, but this case is pretty important. The change is at:
https://github.com/boostorg/unordered/commit/57819d1dd98d23f2a59f59bdb752420b5ae11d52
I'll close this ticket when it's merged to master.
comment:10 by , 9 years ago
This is slower in general, but this case is pretty important
Agreed; prime tables (with MLF 1.0) will always outperform power-two tables with integral keys in the general case, since they produce no collisions. The only exception is if the hash function is guaranteed to be unique in the lower log_2(table_size) bits; in that case unmixed power-two hashing will win. Not sure where I would look to find such use cases (other than the toy insert-consecutive benchmark above), so I am enthusiastic for the above-referenced patch to go in.
comment:12 by , 8 years ago
| Resolution: | → fixed |
|---|---|
| Status: | assigned → closed |
I was wrong - it's the mix64_policy::apply_hash() function - too many collisions while inserting uint64_t values.